Preserving Fronds, not fonds: The Conservation and Digitization of a Fern Album
Picking up from our last blog post on the curious history of the fern album, for this month’s post, we …



Picking up from our last blog post on the curious history of the fern album, for this month’s post, we …

Some of the more curious acquisitions by first City Archivist Major J.S. Matthews have taken time to make fully discoverable …

We have long recognized the importance of increasing accessibility to our City Council Meeting Minutes series (COV-S31), from providing microfilm …

Over the past year or so Archives staff have been working on two long-term projects to improve access to one …
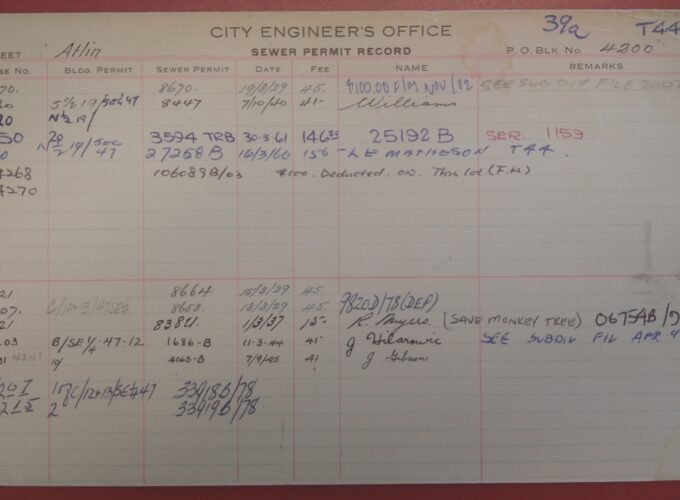
It’s been a while since we’ve posted a Records Roundup for y’all, so we’re due. This series was started in …

A reminder that the Archives will be closed for the holidays at 12:00 noon on Tuesday, December 24th and will …

The Archives is pleased to announce that records of Vancouver’s first and longest-lived neon sign company, Neon Products, are now …

Cased photograph is a term used to describe a class of photographs popularized in the mid-19th century that includes daguerreotypes, …

The Archives is pleased to announce that the entirety of the architectural drawings of the partnerships of Desmond Muirhead, Clive …

You may have heard that Postmedia Network Canada Corporation donated approximately 5.6 million Vancouver Sun and The Province photographic negatives …