

The Archives is pleased to announce that over twelve thousand photographs from the 2010 Olympic Torch Relay (OTR) – showing virtually every torchbearer that participated in the relay – have been processed and are now accessible through our online database. These photographs are part of the Vancouver Organizing Committee for the 2010 Olympic and Paralympic Winter Games (VANOC) fonds, donated in 2010, and may be used for any fair dealing purpose.
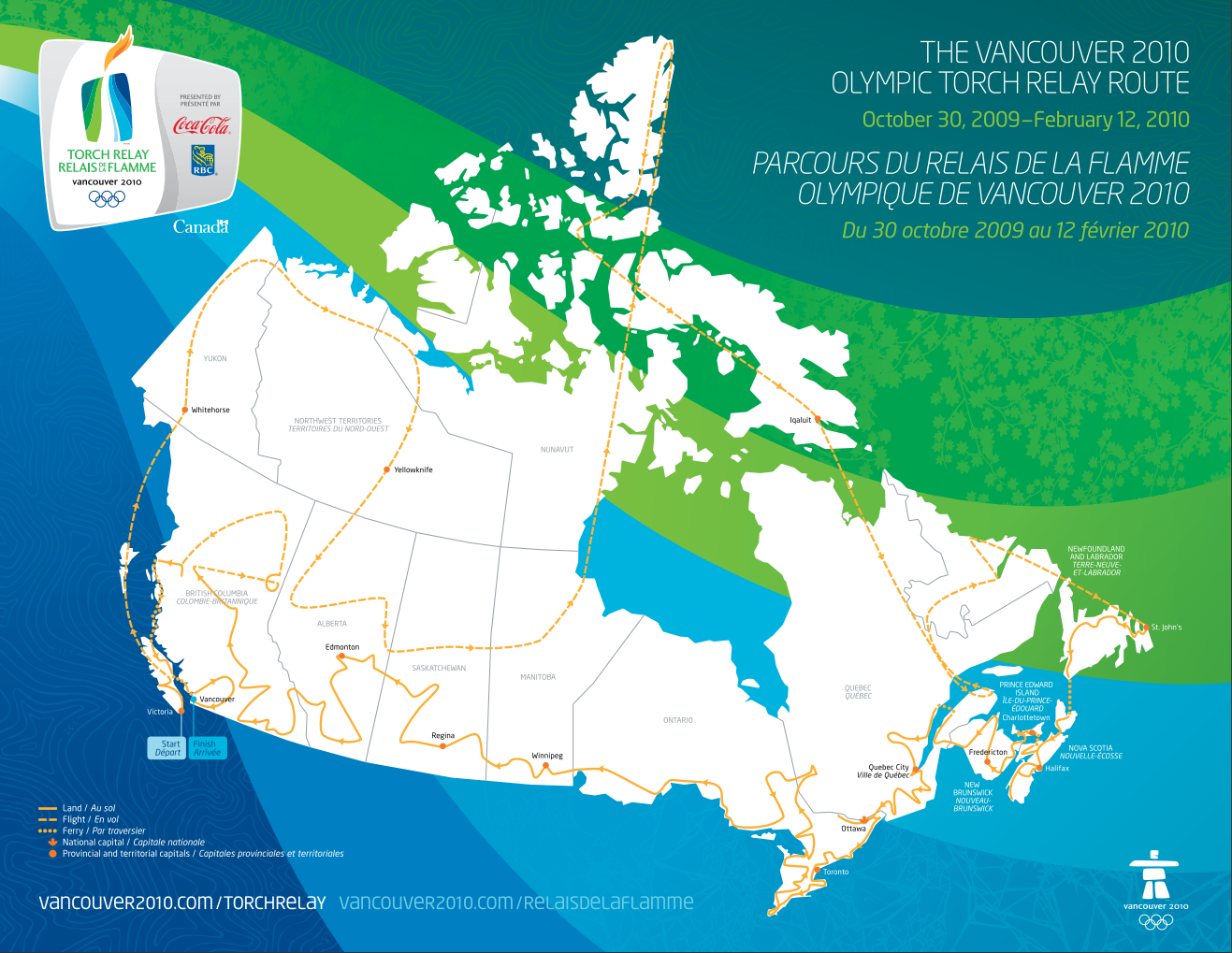
The OTR took place from October 30, 2009 to February 12, 2010. Beginning in Victoria BC, it covered more than 45,000 km across all thirteen provinces and territories before returning to Vancouver 106 days later. Over 12,000 people carried the torch across Canada.
The relay was extensively documented in photographs and video from multiple cameras. As part of their donation, VANOC transferred over 316,000 OTR digital photographs (totaling 1.9 terabytes). These were grouped by relay day, and each day was further broken down into subdirectories that collected highlights of the day to be sent to the OTR’s corporate sponsors, and selections to be used by VANOC for promoting the relay and the games.

The photographs in this series come from each day’s “TB” (torchbearer) folder. VANOC copied a photo of each torchbearer that participated in that day’s relay into the day’s TB folder. Almost every torchbearer is represented in this series (although there are some torchbearers – including the first torchbearer on day 1 – for which no photos were available). There are 12,470 images in this series, but these represent only a small percentage of the OTR photos.

The Olympic Bid Corporation records and VANOC’s analogue records were processed and made available a few years ago, but the torchbearer photographs are the first born-digital records series processed from the VANOC records. Although this series is over 33GB, it represents only a small fraction of the approximately 25TB of born digital records received from VANOC since the conclusion of the Games.

There were a number of reasons that this particular series was chosen as the first series of born-digital records to be processed from the VANOC donation. This project was intended to test our digital preservation capacity – specifically, the ability to ingest large numbers of files and automatically upload access copies and descriptive metadata to our online database (powered by software called Access to Memory, or AtoM for short). The torchbearer photos fulfilled a number of criteria that we were looking for in a test case. The overall arrangement structure was simple, making it easy to structure what are called Submission Information Packages (SIPs) so that they corresponded to logical descriptive units. The content type was uniform, reducing the number of variables that would need to be considered when deciding on a processing configuration, and the number of variables that would need to be considered when troubleshooting inevitable problems. The total size was large enough that it would test the scalability of our digital preservation system, but small enough that it could be completed in a reasonable amount of time, and wouldn’t be overly problematic to troubleshoot when things went wrong. Finally, the content had a strong connection with the Canadian public. There are thousands of photos of Canadians participating in the OTR, and literally millions of people will have a connection to at least one person appearing in the photos.

The original drives received from VANOC were backed up as soon as we received them in 2010. These were later transferred to the Archives’ network storage. This was not straightforward. The original images were created in a Mac environment. The Archives digital preservation system, Archivematica, is primarily Linux-based, and the City network where the storage is mounted is Windows-based. The main difficulty encountered was namespace conflicts among the different operating system environments. This necessitated writing some scripts to resolve the conflicts, and to track and log changes made to the file and directory names.

We discovered that VANOC had helpfully embedded some descriptive metadata in most of the photos about the name of the torchbearer and the segment of the relay. Usually just the torchbearer’s first name and last initial were present; though some had the full name (and others had no name, only the torchbearer number). Frustratingly, there were inconsistencies in fields used to store this metadata, making it impossible to automate the extraction of the metadata to use in the archival descriptions. We extracted the metadata from the images using exiftool, and exported it to a csv file. The descriptive metadata was collected from the various fields that it appeared in and used to create descriptive titles for the images; this was packaged with the SIPs as a csv file that Archivematica could send to AtoM, so that AtoM could create archival descriptions when the access copies were uploaded.
There were 102 SIPs, each corresponding to a single day of the torch relay (although OTR spanned 106 days, four of those were rest days). Each SIP contained a file about the provenance of the SIP’s contents, a file documenting the original directory structure that the SIP contents were copied from, a descriptive metadata file used to populate the AtoM descriptions, and the photos themselves – as few as 8 (day 21), and as many as 270 (day 49).
It took approximately 60 hours, spaced across two weeks, to run all 102 SIPs through Archivematica and upload the images and descriptions into AtoM. Here’s an example of the Archivematica dashboard that shows the various microservices that run on each SIP. These microservices carry out such actions as creating integrity checksums, file format identification and validation, metadata extraction and format migration and normalization. Collectively, these actions help ensure that the source images remain authentic and accessible over time.
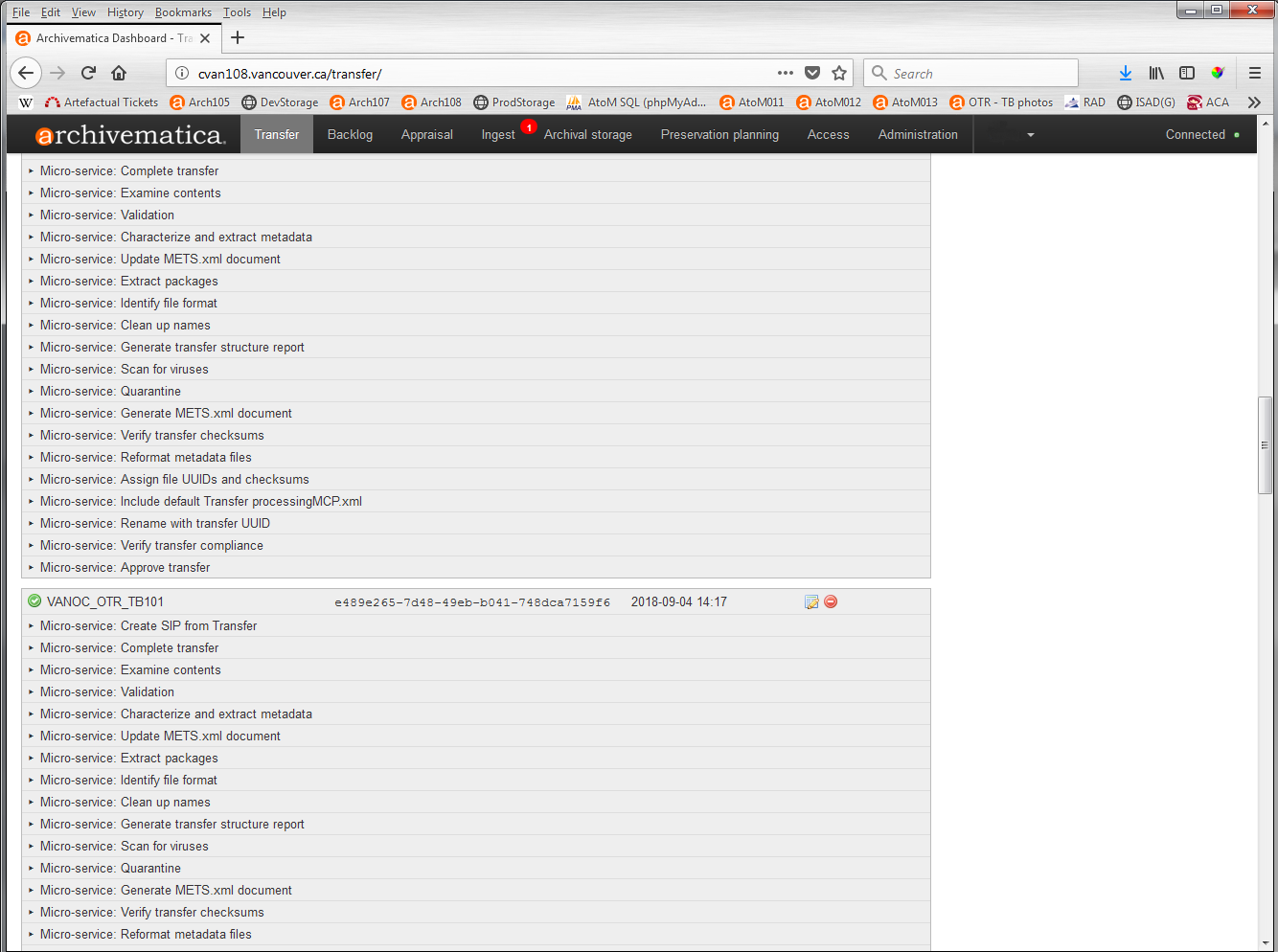
If you are interested in learning more about the nuts and bolts of how Archivematica works, we wrote about it back in 2012.
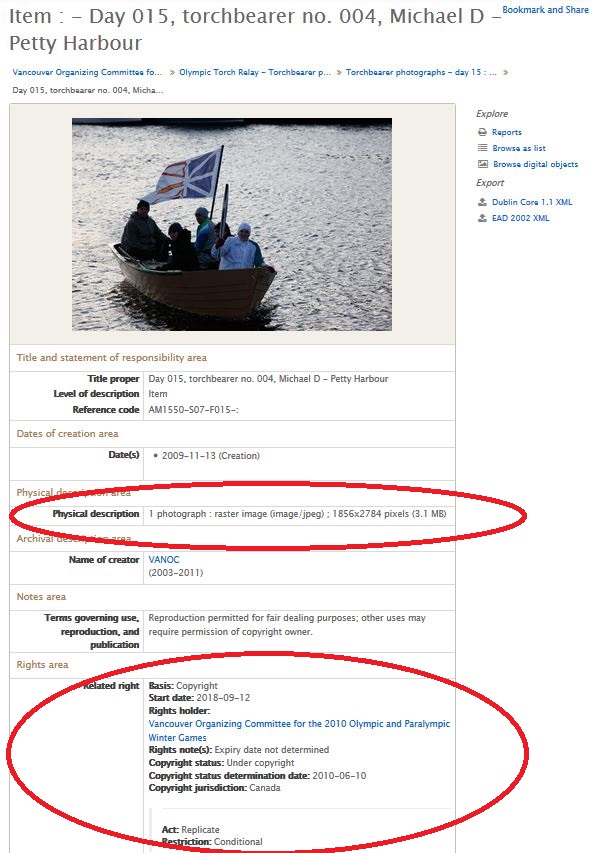
Here is a sample item-level description in AtoM with the access copy attached. The data in the physical description field tells you that the original record is the product of digital photography, that it was born digital. If the description field said something like “1 photograph : b&w acetate negative,” you would know that the digital image was the product of the Archives’ digitization program – a scan of an analogue record. Note also, that the original source image is a jpg file. That is the file format of the digital image received from VANOC, and there is no other version (such as a .tif or raw camera file) available. If you click on the image and agree to fair dealing use, you will be presented with a larger jpg, an exact copy of the original source image.
This was a successful project that validated our procedures and workflow. We are looking forward to building upon this success. There are still more files from the OTR that need to be preserved and made accessible. These include the torchbearer photos from the Paralympic Torch Relay which took place from March 4-12, 2010, VANOC and sponsor selected photos from the OTR, and the OTR video footage. Each of these record series shares some similarities with the torchbearer photos, but will have its own unique challenges. We anticipate making many more VANOC records available in the coming months.





Brilliant. Congratulations. “You done good.”
Interesting is the number of software systems you had to use.
Have any other archives in Canada or US done this, or something like it?
Many archives use Archivematica, but are not necessarily in full production yet. For those that are, we’d love to hear about cases of high-volume born-digital transfers and how that’s working
I was one of the torch carriers in Brantford 2010 and was wondering if there is any place to see pictures? I was told I would be sent a link long ago but only goy a few!
Hi Mary – is this you?
https://searcharchives.vancouver.ca/day-053-torchbearer-no-175-mary-l-brantford
Hello I was a torch bearer Day 054, torchbearer no. 124, Brandon Z – Blenheim. I was wondering how I might aquire a torch from the relay if possible as at the time i couldn’t afford to purchase my torch i used and maybe a new outfit as I have since lost my outfit thanks
Hello Brandon. We’re not sure how long Games-related relay items are available, but you could try contacting the Canadian Olympic Committee directly: https://olympic.ca/contact-us/
Hi my name is Donna Larade and I was a torch bearer in Paquentkek First Nations in Nova Scotia and was wondering where I could go and see pictures of myself I was supposed to be sent a link and never received one? Can you help me with this please?
Hello Donna. This photo may be of you (VANOC only publicly identified torchbearers by first name and surname initial): https://searcharchives.vancouver.ca/day-019-torchbearer-no-015-donna-l-paqtnkek . And here is a link to all the Day 19 torchbearer photos we have available: https://searcharchives.vancouver.ca/torchbearer-photographs-day-19