This past November I attended the 2016 conference of the Association of Moving Image Archivists (AMIA). It took place in Pittsburgh, Pennsylvania – the City of Bridges. Here are a few of the highlights.

HACK DAY
A pre-conference tradition since 2013 is the AMIA/DLF (Digital Library Federation) Hack Day, wherein participants collaborate on short projects to develop solutions to various problems associated with moving image preservation and access. Hack Day is a free event focused on practical outcomes and skill-sharing amongst developers and non-developers. This year’s projects included:
- Checksumthing, a Python script to transform the data inside checksum sidecar files to the archivist’s desired format. The project won two awards – Best Solution to the Stated Problem and the audience favourite award.
- Loggr, a schema and template for logging audiovisual artifacts (errors, usually visual, introduced during the digitization process) using consistent terminology. Loggr can help archivists create reports on the frequency and severity of artifacts in order to prioritize quality control work.
- Linked Film Description Framework, a linked open data driven web resource that retrieves descriptive information about film titles from resources listed in Wikidata;
- Wikidata for Digital Preservation, a contribution to an ongoing project to describe file formats, software, and other elements of digital preservation as structured data on Wikidata. This team created a crosswalk that compared existing audiovisual file format properties in Wikidata with properties from other sources of format description, and made recommendations for new properties to be added to Wikidata. I participated in this team, and we won an award for best embodiment of the Hack Day Manifesto!
AFTER DIGITIZATION
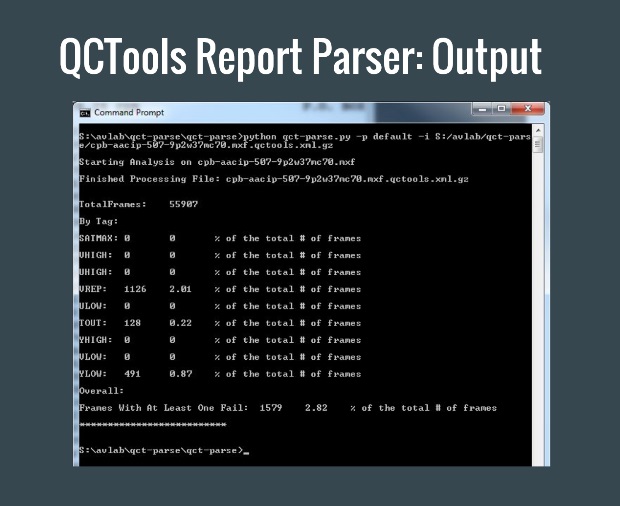
A common misconception among non-archivists is that for fragile or obsolescent media, digitization is “the end” – that once media are digitized, the preservation and access problems are solved. In reality, the new digital file requires just as much (if not more!) management and care as the physical item for which it is a surrogate. Many of this year’s sessions focused on the work that needs to be done after digitization. Brendan Coates of the University of California Santa Barbara and Morgan Morel of George Blood Audio Video presented QCT-Parse, a series of scripts for automating actions in QCTools. QCTools is open-source software for performing quality control on digitized video files, and QCT-Parse includes scripts for generating, then parsing a QCTools report in order to speed up quality control work. QCT-Parse is a wonderful example of the way open source allows members of the preservation community to build upon one another’s tools, and I look forward to exploring its application to our quality control workflows here at CVA.
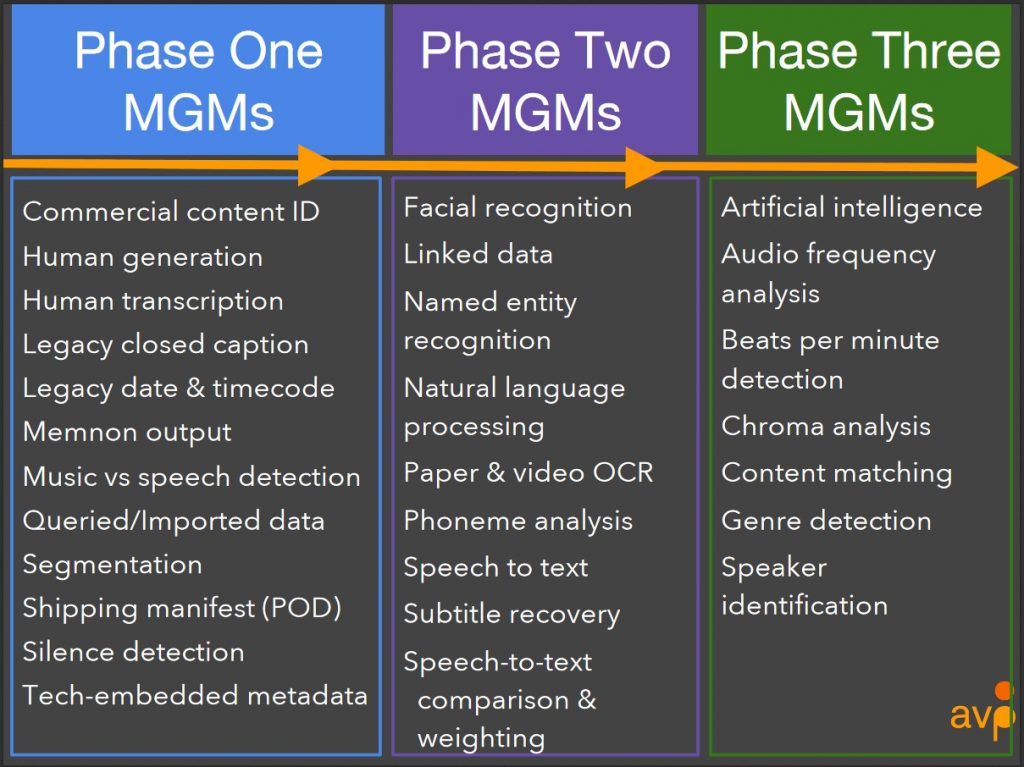
Chris Lacinak of AVPreserve and Jon Dunn of Indiana University presented on Indiana University’s Media Digitization and Preservation Initiative, which is now addressing the challenge of mass description following mass digitization. In order for researchers to be able to discover digitized audiovisual content, description needs to be sufficiently granular, and IU is exploring how best to harness multiple existing sources of metadata and emergent technologies like facial recognition and content matching to generate meaningful descriptions on a large scale. I look forward to seeing how outcomes from this project might apply to the rest of the field.
DIGITAL PRESERVATION STREAM
There was also a curated stream dedicated to the digital preservation of audiovisual content – a very timely topic as more and more organizations amass digital AV through digitization projects and acquisition of born-digital records. The stream was spearheaded and curated by Kathryn Gronsbell of the Carnegie Hall Archives, Shira Peltzman of UCLA, Ashley Blewer of the New York Public Library, and Rebecca Fraimow of WGBH and the American Archive of Public Broadcasting. This stream was particularly relevant for me as I’m currently tackling over twelve terabytes of born-digital video created in the making of GVTV in the late 1990s and early 2000s.
Anne Gant of Amsterdam’s EYE Filmmuseum spoke about the challenges of acquiring and accessioning born-digital moving image donations, including the need to allocate more staff time to up-front activities like checking hard drives upon receipt. Tim Babcock of Penn State talked about establishing a digital preservation program from scratch, and addressed the intimidation beginners can feel in the face of daunting best-practice documents and the courage we all need to be open about our digital preservation practices so we can learn together. This sentiment was echoed across the Digital Preservation stream and the Do-It-Yourself Community Archiving Symposium which ran concurrently (and which was kindly recorded and posted for those who couldn’t attend the conference or, like me, were busy in the Digital Preservation stream).
Together with Tom De Smet of the Netherlands Institute for Sound & Vision, Dinah Handel of the New York Public Library, and Travis Wagner of the University of South Carolina, I participated in a theory-versus-practice panel that addressed the distance between expectations and realities of digital preservation work, and the sometimes limited applicability of standards and codified best practices to practitioners’ real-life situations. I spoke about the early stages of my work on GVTV, including creation and analysis of disk images containing thousands of video files, and, in the spirit of openness, took audience members on a play-by-play of everything that didn’t work the way I thought it would. It was great to exchange stories and ideas with my fellow panelists and other conference attendees, and I returned to Vancouver ready to dig in to GVTV with renewed vigour.
AMIA conferences draw attendees from all over the world, and the annual conference is a great opportunity to compare notes with others in the field and keep current with the latest developments in moving image archives professional practice.