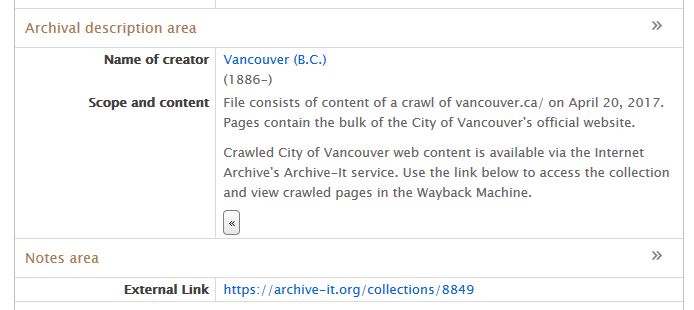
We are pleased to announce that we have begun preserving and providing access to crawls (snapshots) of the City’s website using Archive-It, a web application developed and managed by the Internet Archive. Archive-It uses an open-source crawler called Heritrix to crawl specific web content based on instructions provided by the user (in our case, that’s us), and the venerable Wayback Machine to provide access. Over time, the preserved crawls will show how the City’s website has changed in terms of content, look and feel.

How it works
Each crawl directs Heritrix to one or more “seed” URLs, which you can think of as the starting points of the crawl. From each seed, Heritrix browses through all links and saves any content it encounters that falls within the scoping rules for the crawl. Crawled content is saved in the WARC file format, an ISO standard for storing web content.
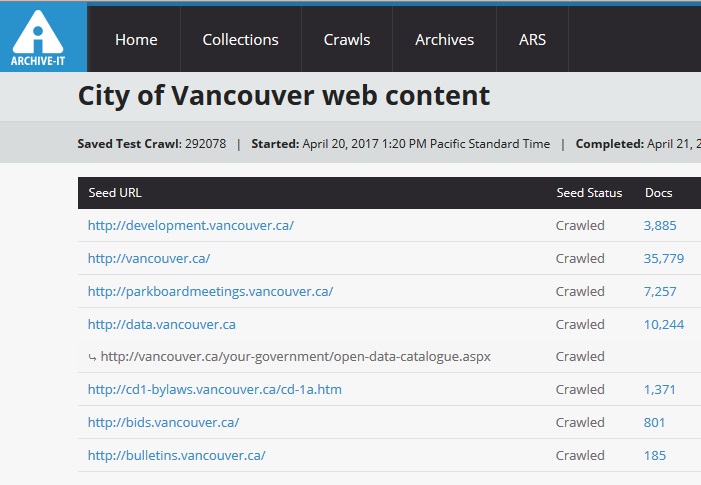
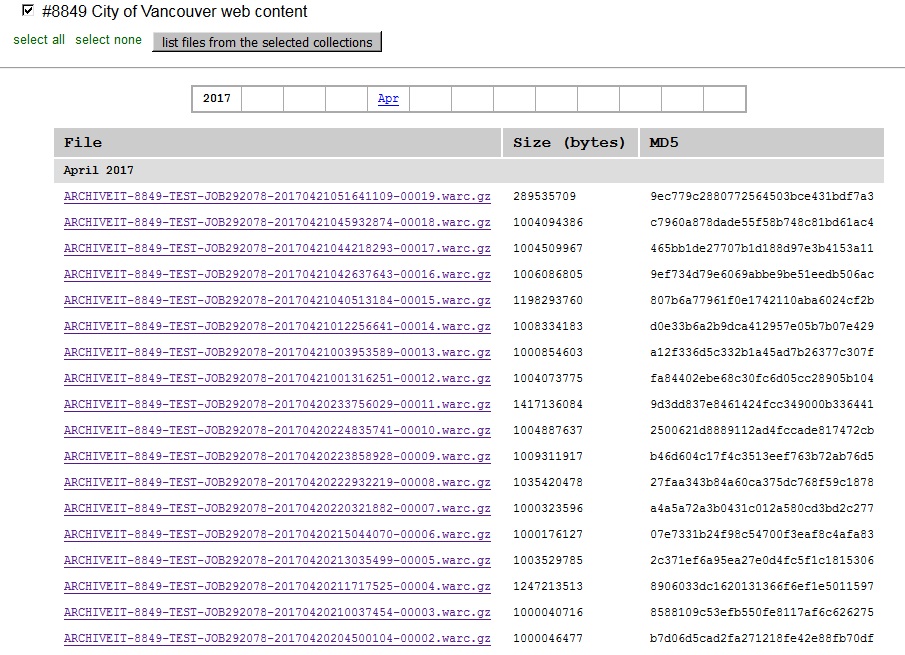
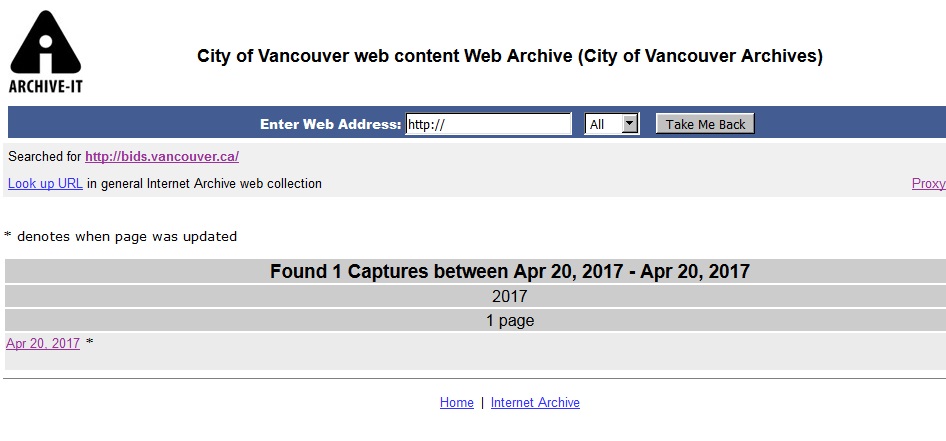
We are preserving the resulting WARC files in-house using our digital preservation system, Archivematica. However, the WARC format stores chunks of content somewhat arbitrarily, and providing meaningful access to the content of WARC files requires highly specialized software and expertise. That’s where the Archive-It service really shines – all crawled content can be viewed via the Wayback Machine, just as if you were browsing the live web. To get started, visit our City of Vancouver web content collection page and select which URL you would like to use as your access point.
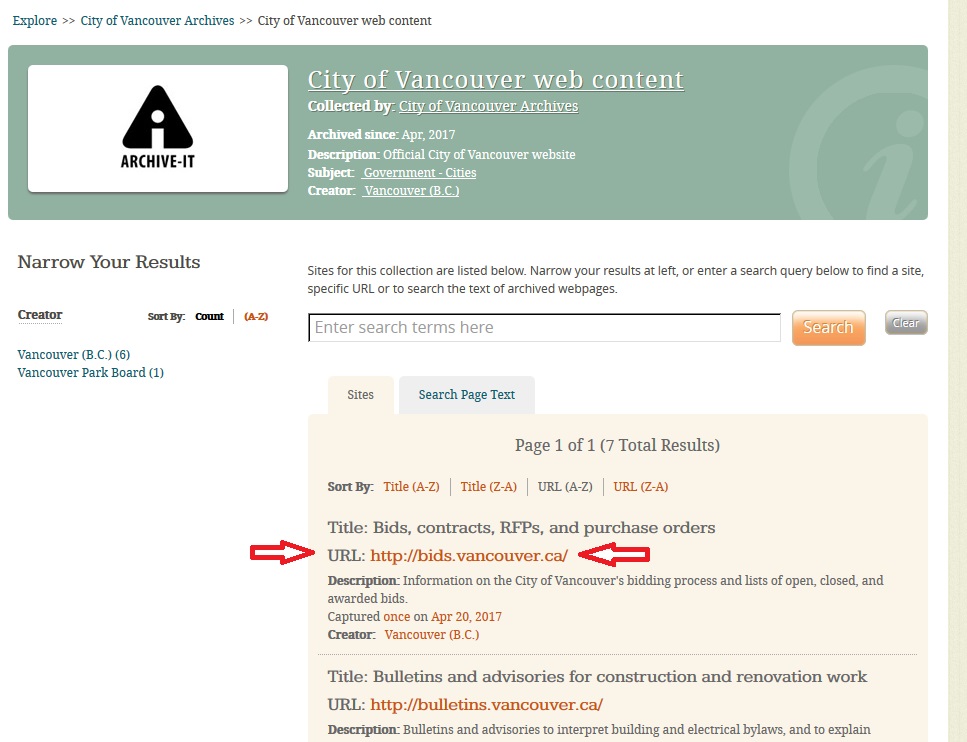
From there, you will see how many times the URL has been captured, and on which dates. Selecting a date will open the content in Wayback.
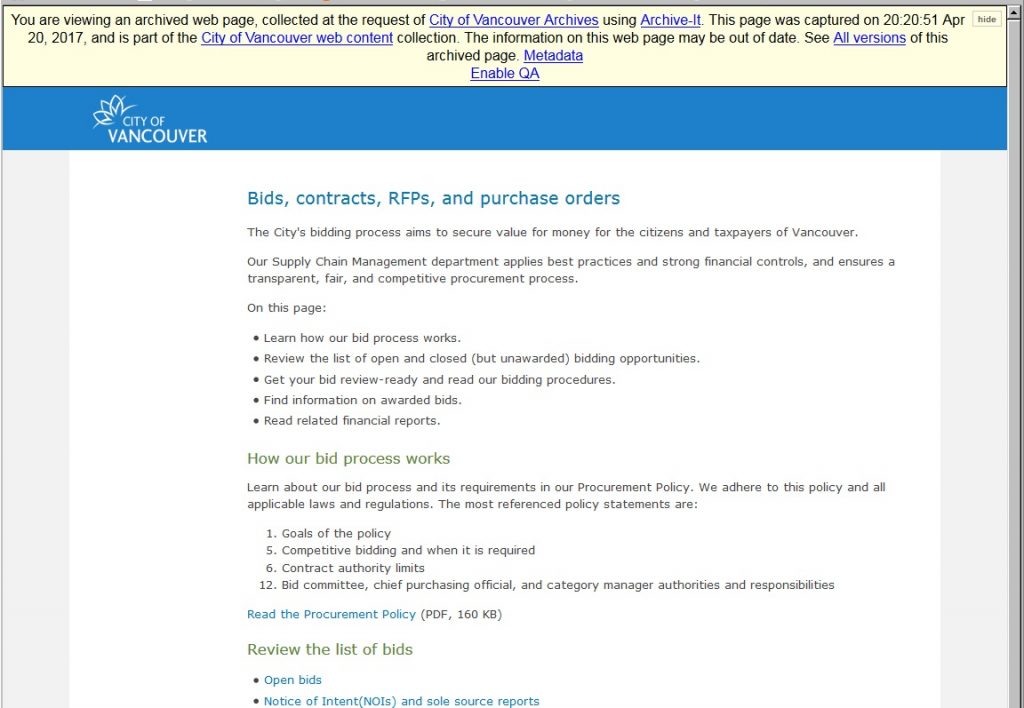
When you are viewing the content in Wayback, a handy banner will appear to show you the date and time of capture and remind you that you’re not looking at a current page!
How it doesn’t work
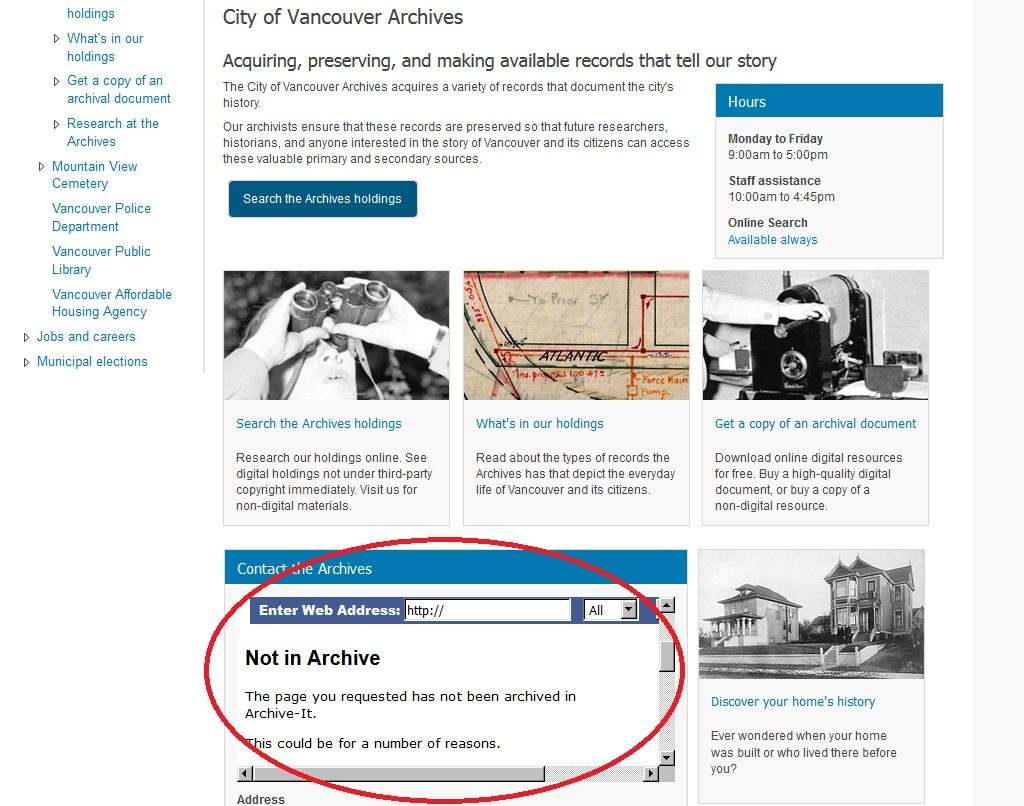
Search boxes and some drop-down navigation do not work in Wayback the way they do on the live web, and interactive content such as contact forms will not display. Instead, you will see a “Not in Archive” notice.
Some content has been excluded from the crawl because the nature of the content – often a searchable calendar or complex database – creates what’s known as a “crawler trap.” A crawler trap causes the crawler to get stuck in an infinite loop as it attempts to try every possible combination of factors and save the result. Examples of crawler traps include the Park Board’s recreation calendar system and our very own database, searcharchives.vancouver.ca! For this reason, you won’t see this content in the crawls.
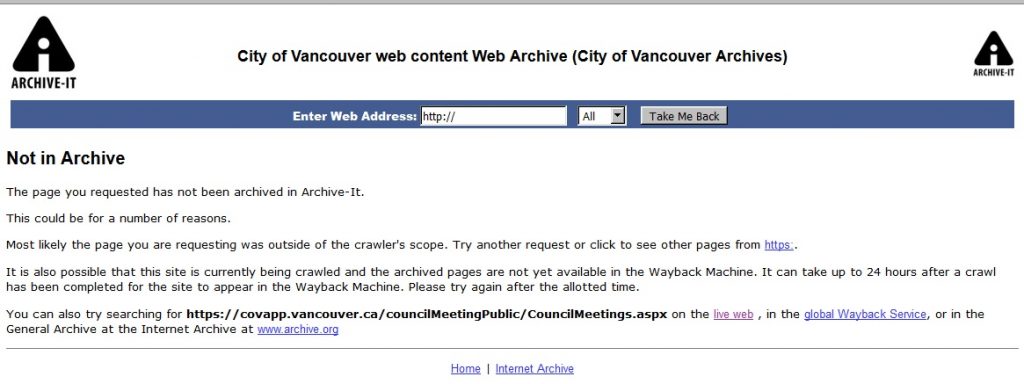
Another area of trouble for Heritrix is content that relies heavily on JavaScript in the underlying code (interested folks can read more about that here). We encountered this problem during test crawls, primarily with the part of the site where council minutes and agendas are posted. When you attempt to navigate to this content in Wayback, you will see the “Not in Archive” notice and be able to link to the URL in its current state on the live web.
You can also discover crawled web content via our online database, searcharchives.vancouver.ca, and link to our Archive-It collection page from there.
We welcome your feedback and questions about using Archive-It to access legacy web content. Happy browsing!